Un grupo de investigadores de Google ha creado VLOGGER, una nueva herramienta de inteligencia artificial que toma una imagen fija y es capaz de convertirla en un avatar animado y controlable. Se trata de un enfoque en la generación de vídeo algo diferente al de Sora, de OpenAI, pero podría tener muchas aplicaciones.
VLOGGER es un modelo de IA capaz de crear un avatar animado a partir de una imagen fija y mantener el aspecto fotorrealista de la persona de la foto en cada fotograma del vídeo final. Ya se pueden hacer cosas parecidas hasta cierto punto con herramientas como la sincronización labial de Pika Labs, pero esta parece ser una opción más sencilla y que consume una menor cantidad de ancho de banda.
El modelo también toma un archivo de audio de la persona que habla y controla el movimiento del cuerpo y los labios para reflejar la forma natural en que esa persona se movería si fuera ella quien dijera las palabras. Esto incluye la creación de movimientos de cabeza, expresión facial, mirada, parpadeo, así como gestos con las manos y movimientos de la parte superior del cuerpo sin ninguna referencia más allá de la imagen y el audio.
Actualmente VLOGGER no se puede probar, ya que no es más que un proyecto de investigación con varios vídeos de demostración, pero si algún día se convierte en un producto podría ser una nueva forma de comunicarse en apps para trabajo en equipo como Slack o Teams.
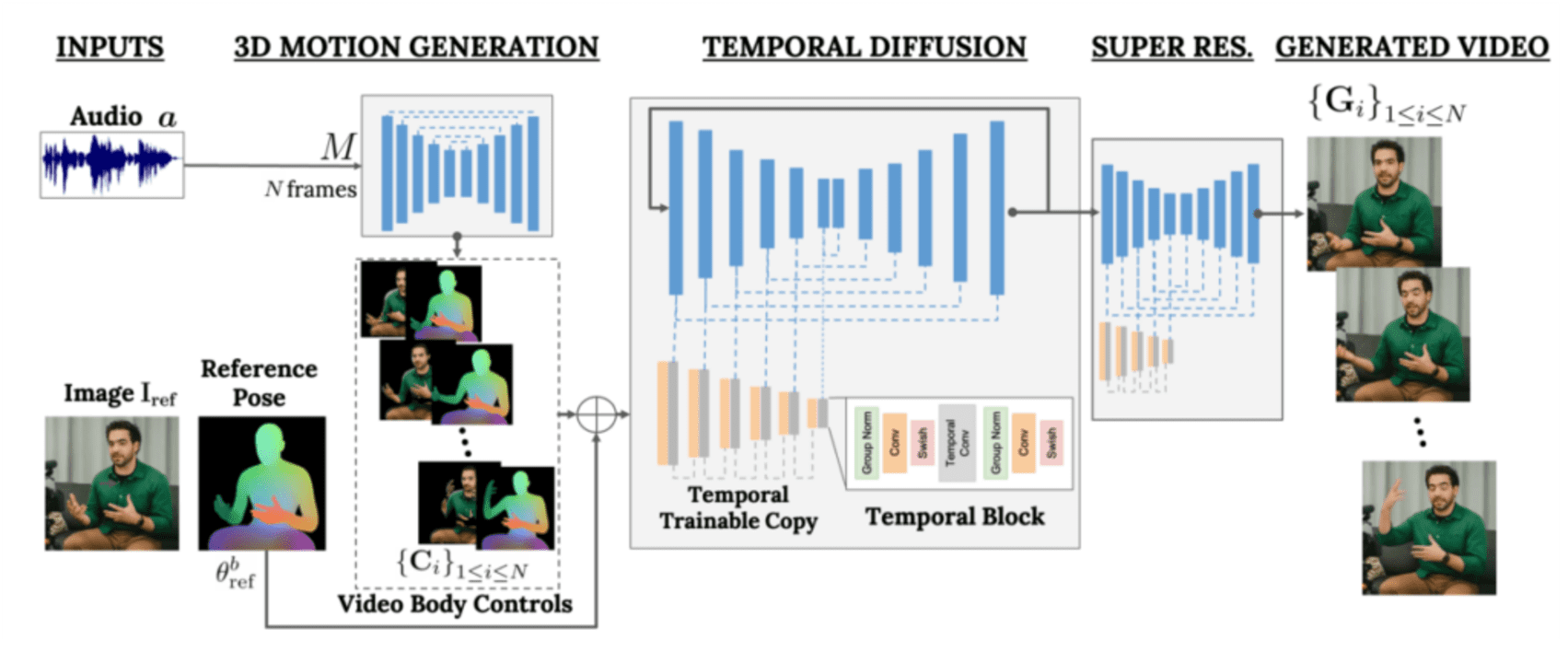
VLOGGER se basa en la arquitectura de difusión que impulsa los modelos de texto a imagen, vídeo e incluso 3D, como MidJourney o Runway, pero añade mecanismos de control adicionales. Para generar el avatar, VLOGGER sigue una serie de pasos: primero toma el audio y la imagen como datos de entrada, los somete a un proceso de generación de movimiento 3D, luego a un modelo de “difusión temporal” para determinar los tiempos y el movimiento, y por último se aumenta la escala y se convierte en el resultado final.
Para entrenar el modelo fue necesario un gran conjunto de datos multimedia llamado MENTOR, que contiene 800.000 vídeos de diferentes personas hablando con cada parte de su cara y cuerpo etiquetada en cada momento.

