
Nvidia ha presentado su último chip de inteligencia artificial (IA) llamado Blackwell B200 que, según afirma, puede realizar algunas tareas 30 veces más rápido que su predecesor. Esto hará estallar el sector de la IA en los próximos años.
De esta forma anunció ayer la compañía americana de chips que lanzaban al mercado una tarjeta para servidores que revolucionaría el campo de la IA, gracias a sus enormes capacidades y potencial desatado.
El imprescindible chip de IA H100 de Nvidia la convirtió en una empresa multimillonaria. Y ahora Nvidia está a punto de ampliar su ventaja con la nueva GPU Blackwell B200 y el “superchip” GB200.
Cómo han conseguido diseñar la nueva GPU Blackwell B200
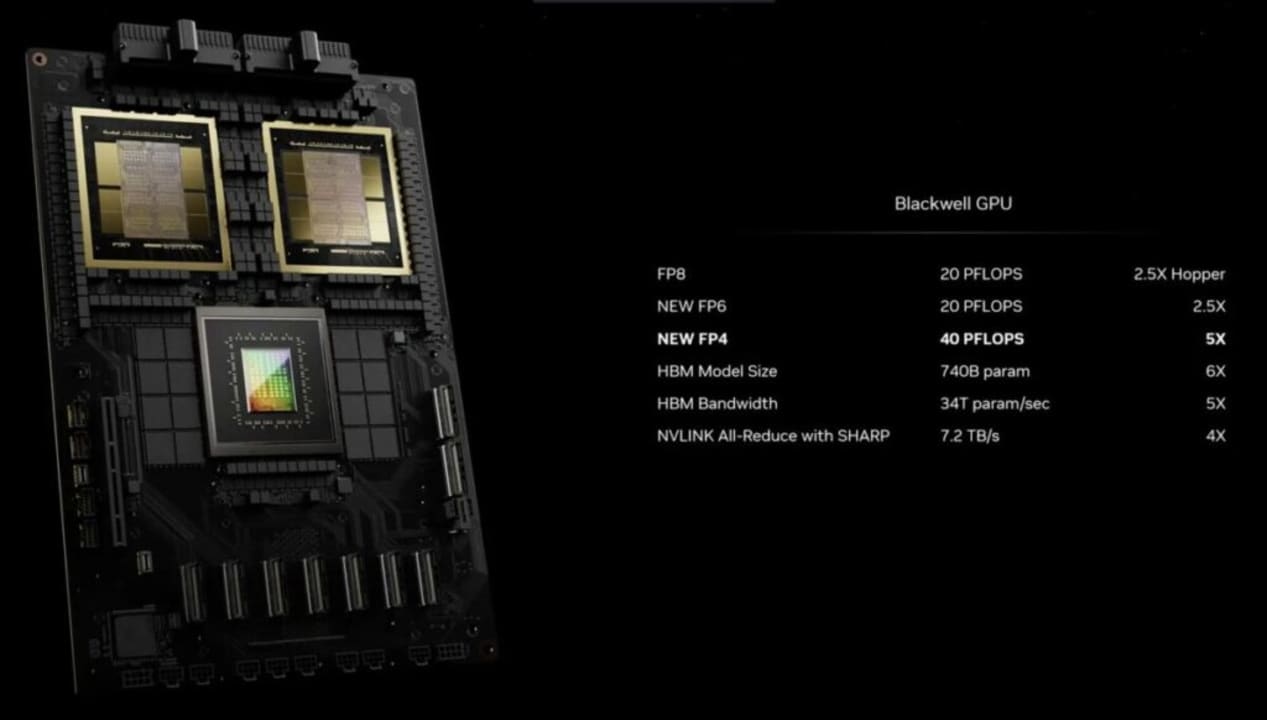
Nvidia afirma que la nueva GPU B200 ofrece hasta 20 petaflops de potencia FP4 gracias a sus 208.000 millones de transistores. Además, afirma que una GB200 que combine dos de esas GPU con una única CPU Grace puede ofrecer 30 veces más rendimiento para cargas de trabajo de inferencia LLM y, al mismo tiempo, ser sustancialmente más eficiente.
Según Nvidia, “reduce el coste y el consumo de energía hasta 25 veces” con respecto a una H100. Según Nvidia, para entrenar un modelo de 1,8 billones de parámetros antes se necesitaban 8.000 GPU Hopper y 15 megavatios de potencia. Hoy, el director general de Nvidia afirma que 2.000 GPU Blackwell pueden hacerlo consumiendo solo cuatro megavatios.
En una prueba GPT-3 LLM con 175.000 millones de parámetros, Nvidia afirma que la GB200 tiene un rendimiento algo más modesto, siete veces superior al de una H100, y afirma que ofrece cuatro veces más velocidad de entrenamiento.
Nvidia explicó a los periodistas que una de las mejoras clave es un motor transformador de segunda generación que duplica el cálculo, el ancho de banda y el tamaño del modelo utilizando cuatro bits para cada neurona en lugar de ocho (de ahí los 20 petaflops de FP4 que he mencionado antes).
Una segunda diferencia clave solo se produce cuando se conectan grandes cantidades de estas GPU: un conmutador NVLink de última generación que permite que 576 GPU se comuniquen entre sí, con 1,8 terabytes por segundo de ancho de banda bidireccional.
Para ello, Nvidia ha tenido que crear un chip de conmutación de red completamente nuevo, con 50.000 millones de transistores y parte de su propia capacidad de cálculo integrada: 3,6 teraflops de FP8, dice Nvidia.
Según Nvidia, antes un clúster de solo 16 GPU dedicaba el 60 por ciento de su tiempo a comunicarse entre sí y solo el 40 por ciento a la computación real.
Nvidia cuenta con que las empresas compren grandes cantidades de estas GPU, por supuesto, y las está empaquetando en diseños más grandes, como el GB200 NVL72, que conecta 36 CPU y 72 GPU en un único bastidor refrigerado por líquido para un total de 720 petaflops de rendimiento de entrenamiento de IA o 1.440 petaflops de inferencia. Tiene casi tres kilómetros de cables en su interior, con 5.000 cables individuales.
No hemos oído nada de nuevas GPU para gaming, ya que esta noticia se produce en la Conferencia sobre Tecnología para GPU de Nvidia, que suele centrarse casi por completo en el GPU Computing y la IA. Pero es probable que la arquitectura de GPU Blackwell también alimente una futura línea de tarjetas gráficas de sobremesa de la serie RTX 50.

